In The Air Model Rendering
Cameras and Transforms
When I designed the render engine I sneakily intended to pass in a WorldState object
that describes ... the state of the world. The render function looks like
#![allow(unused)] fn main() { pub fn render(gl: &Context, renderer_state: &RendererState, world_state: &WorldState) }
Which looks like:
#![allow(unused)] fn main() { pub struct WorldState { pub time: f32, } }
Time to think about what we should put in it! Clearly we need a camera. It can probably look something like:
#![allow(unused)] fn main() { struct Camera{ world_transform: glam::Transform3D, fov: f32, near: f32, far: f32 } }
We probably also need something to represent a model:
#![allow(unused)] fn main() { enum MeshType { Vehicle, ... } enum TextureType { VehicleAlbedo, VehicleMetalRoughness, ... } struct BasicOpaqueMaterial { albedo: Option<TextureType>, metal_roughness: Option<TextureType> } enum MaterialType { BasicOpaqueMaterial(BasicOpaqueMaterial) } struct Model { world_transform: glam::Transform3D, mesh: MeshType material: MaterialType::BasicOpaqueMaterial(BasicOpaqueMaterial { albedo: TextureType::VehicleAlbedo, metal_roughness: TextureType::VehicleMetalRoughness, }) } .... const player_vehicle = Model{ transform: ... mesh: MeshType::Vehicle, material: MaterialType::BasicOpaqueMaterial() } }
Uh, wow. That's pretty terrible looking. Then all those enums need to be turned into references in the resources structs. There'd be a lot of boilerplate in adding new resources.
So how can we handle resources and pointers at those resources? We could use hashmaps and strings - but that can't be statically checked and has a runtime cost.
Another option ould be to put all the resources inside a ReferenceCounter so they can be referenced directly from multiple places.
To be honest, it wouldn't be so bad if we didn't have to define all those enums. What if we could have them all predefined to reduce the boilerplate? Can we use a cargo build script to generate the resource structs and accessor functions?
But I'm planning to render like maybe 5 different objects, so this whole thing is a bit academic. I'm not building a general-purpose-rasterizer, I'm building a demo. So I'm going to .... just write render object functions directly in the rasterizer.
So my worldstate object will look like:
#![allow(unused)] fn main() { struct Vehicle { transform: glam::Transform3D; linear_velocity: glam::Vec3, angular_velocity: glam::Vec3 } struct Camera { transform: glam::Transform3D; fov: f32, near: f32, far: f32, } struct WorldState { vehicles: Vec<Vehicle>, camera: Camera, } }
And in the rasterizer I'll probably a function something like:
#![allow(unused)] fn main() { fn render_vehicle(gl: &Context, vehicle: &Vehicle) { } }
No good for a big game with hundreds of objects, but should be fine for this demo.
And after a bit of fiddling with shaders (copying most of it from the Pilot game),
and then an hour to find that I had forgotten to enable depth testing, and we have:
The render function looks like:
#![allow(unused)] fn main() { pub fn render_gbuffer( gl: &Context, renderer_state: &RendererState, world_state: &WorldState, camera_matrices: &CameraMatrices, ) { // Render Opaque geometry to the G-buffer renderer_state.framebuffers.gbuffer.bind(gl); unsafe { gl.viewport( 0, 0, renderer_state.resolution[0], renderer_state.resolution[1], ); gl.clear_color(0.0, 0.0, 0.0, 0.0); gl.clear(glow::COLOR_BUFFER_BIT | glow::DEPTH_BUFFER_BIT); } let active_shader_program = &renderer_state.shader_programs.model; let active_mesh = &renderer_state.static_resources.meshes.vehicle_med_res; active_shader_program.bind(gl); active_mesh.bind(gl, &active_shader_program.attributes); unsafe { gl.uniform_matrix_4_f32_slice( active_shader_program.uniforms.get("camera_to_world"), false, &camera_matrices.camera_to_world.to_cols_array(), ); gl.uniform_matrix_4_f32_slice( active_shader_program.uniforms.get("world_to_camera"), false, &camera_matrices.world_to_camera.to_cols_array(), ); gl.uniform_matrix_4_f32_slice( active_shader_program.uniforms.get("camera_to_screen"), false, &camera_matrices.camera_to_screen.to_cols_array(), ); } renderer_state .static_resources .textures .vehicle_albedo .bind_to_uniform(gl, 0, active_shader_program.uniforms.get("albedo_texture")); renderer_state .static_resources .textures .vehicle_roughness_metal .bind_to_uniform( gl, 1, active_shader_program .uniforms .get("metallic_roughness_texture"), ); for vehicle in world_state.vehicles.iter() { unsafe { gl.uniform_matrix_4_f32_slice( active_shader_program.uniforms.get("world_to_model"), false, &vehicle.transform.to_cols_array(), ); gl.uniform_matrix_4_f32_slice( active_shader_program.uniforms.get("model_to_world"), false, &vehicle.transform.inverse().to_cols_array(), ); } active_mesh.render(gl); } } }
So I set up the shader for the vehicle once, and then render it a bunch of times. Plenty of room for optimization here:
- I can shift what I compute on CPU vs GPU.
- I could use draw instances to render lots within a single draw call.
But I'm not fussed about that yet.
I twiddled my compositing function in the "lighting" pass as well. It now looks like:
void main() {
vec2 uv = screen_pos.xy * 0.5 + 0.5;
vec4 color = texture(buffer_color, uv);
vec4 geometry = texture(buffer_geometry, uv);
vec4 material = texture(buffer_material, uv);
vec4 outCol = vec4(0.0, 0.0, 0.0, 1.0);
outCol += color * sin(0.5 * 3.14159 * 2.0 * 0.0);
outCol += geometry * sin(0.5 * 3.14159 * 2.0 * 0.33333);
outCol += material * sin(0.5 * 3.14159 * 2.0 * 0.66666);
FragColor = outCol;
}
Why did I do this? Well, I wanted to see the performance impact of sampling all three buffers across the entire screen. The good news is it still hits a smooth frame rate at 1080p. (I think it is 60FPS, but I haven't measured). This means my integrated GPU is keeping up with the bandwidth requirements - which was a bit of a worry as it is the main disadvantage of a deferred pipeline.
I was curious as to how much of my GPU I'm using to render just this basic scene, so I fired
up intel_gpu_top, and:
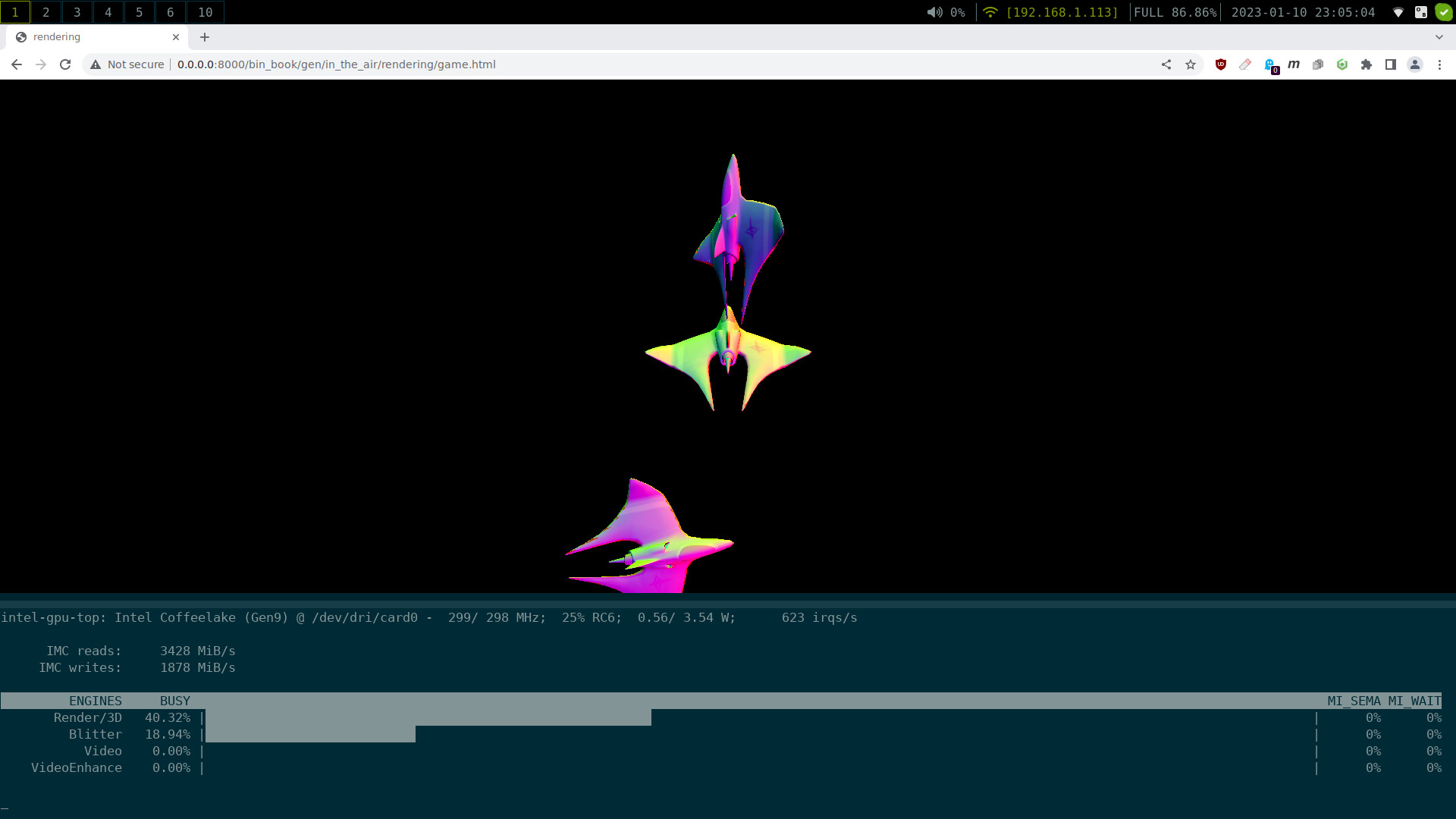
The render engine claims it is 40% busy, and we're using 3,428MiB/s of memory bandwidth. How close is this to capping out? Well, my laptop is DDR4, and it's ram is clocked at 2666Mt/s with a 64 bit bus. This gives it a theoretical rate of 170,624 Mbits/s or 21,328MiB/s. This suggests we are using ~16% of the processors memory bandwidth. I am suspicious of these calculations - take it with a large grain of salt.
What's next? Well, I need to check I've got all my transforms right and then it's on to rendering those clouds.
(I checked my transforms, discovered I had got a bunch wrong and fixed them. I had forgotten that an objects "world transform" matrix describes how to transform a vector from object-space into world-space not the other way around. Thus the matrix is the "model_to_world" matrix in the way I like to name them. Sometimes I wonder if I should name matrices using "in" instead of "to". It would make the multiplication read nicer as well).